
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
 Grundlagen I: Übersicht Grundlagen I: Übersicht
|
Daten-Scouts - Recherche in der "globalen Bibliothek"1. Lost in CyberspaceDie gern gebrauchte Metapher von der "globalen Bibliothek" mag für das World Wide Web einigermaßen zutreffend sein, handelt es sich doch um eine kaum überschaubare, täglich wachsende Ressourcenbasis. Was das World Wide Web jedoch von herkömmlichen Bibliotheken maßgeblich unterscheidet, ist zum einen seine dezentrale Organisation: Jeder publikationsfreudige Computerbesitzer mit Internetzugang kann den "Bibliotheksbestand" zu jeder Zeit um neue Ressourcen erweitern, ohne zuvor bei einer "Bibliotheksverwaltung" die Erlaubnis hierfür einholen zu müssen; zum anderen (und als Folge der dezentralen Organisation) verfügt das World Wide Web über keinen zentralen Katalog bzw. eine zentrale Systematik, welche das Auffinden der verfügbaren Dokumente erlaubt. Daher gleicht das World Wide Web am ehesten der labyrinthischen Bibliothek der namenlosen Abtei aus Umberto Ecos "Der Name der Rose": "Die Bibliothek ist ein großes Labyrinth, Zeichen des Labyrinths der Welt. Trittst du ein, weißt du nicht, wie du wieder herauskommst." Aufgrund der dezentralen Organisation des Webs sind die verfügbaren Ressourcen prinzipiell nur auf zweierlei Weise auffindbar: Entweder man kennt als Suchender den exakten URL eines Dokuments (was voraussetzt, dass man über dessen Existenz bereits im Bilde ist), oder man findet ein Dokument (von dessen Existenz man bis dato noch nichts wusste) dadurch, dass man einem Link in einem bereits bekannten bzw. gefundenen Dokument folgt. Zwar gibt es Berechnungen, die besagen, dass zwei beliebige Dokumente im World Wide Web statistisch betrachtet nie mehr als 19 "Klicks" von einander entfernt liegen, doch erscheint es angesichts vieler Millionen von im Netz verfügbaren Dokumenten als relativ aussichtslos, bei einer gezielten Themensuche ausgehend von einem bekannten Dokument genau die richtigen 19 "Klicks" zu tätigen, um schließlich zu einem anderen Dokument zu gelangen, welches genau diejenige Information bereithält, derer man gerade bedarf. Resultat eines solchen Online-Recherchierens nach dem "Schneeballsystem" ist in der Regel nicht ein Gefühl der Befriedigung, sondern das oft beschriebene - und eher frustrierende - "Lost in Cyberspace". 2. Suchdienste: Orientierungshilfen für die "globale Bibliothek"Suchdienste sind Dienstleistungsangebote im World Wide Web, die es sich zur Aufgabe gemacht haben, ihren Nutzern bei der Online-Recherche mehr als nur Zufallstreffer mit dem Schneeball zu ermöglichen. Suchdienste archivieren die URLs von so vielen WWW-Dokumenten als möglich. Darüber hinaus (und das ist das eigentlich wichtige) sind den URLs im Archiv Beschreibungen hinsichtlich verschiedener Kriterien beigegeben (z.B. Titel und Inhalt des betreffenden Dokuments). Über thematische Rubriken und/oder eine Suchmaske erhalten Nutzer Zugriff auf diesen Datenbestand. Je nach ausgewählter Rubrik und/oder dem eingegebenen Suchterm wird als Suchergebnis eine Menge an URLs aus dem Datenbestand ausgegeben, die von den Betreibern des jeweiligen Suchdienstes bzw. dem verwaltenden Programm für zu dieser Rubrik bzw. diesem Suchterm passend erachtet werden. Informationssuchende können sich somit aus dem Archiv eines Suchdienstes eine Auswahl an WWW-Angeboten zusammenstellen lassen, indem sie ihre Interessen über eine Suchanfrage deklarieren. Häufig ist in bezug auf Online-Suchdienste aller Art der Oberbegriff der "Suchmaschinen" gebräuchlich. Im engeren Sinne können jedoch nur Suchdienste eines bestimmten Zuschnitts als Maschinen bezeichnet werden (nämlich solche Dienste, bei welchen Computerprogramme für das Suchen und Sammeln von WWW-Seiten zuständig sind). Neben den Suchmaschinen stehen die sogenannten "Web-Kataloge", bei welchen das Sammeln und Archivieren von WWW-Seiten in den Händen von Menschen liegt. Daher ist es im allgemeinen sinnvoller, unspezifiziert von Suchdiensten zu sprechen und diesen dann zum einen die Web-Kataloge und zum anderen die Suchmaschinen als zwei je spezifisch organisierte Typen unterzuordnen (vgl. die Veranschaulichung in Abb. 1).  Abb. 1: Unterschiedliche Typen von Suchdiensten. Web-Kataloge und Suchmaschinen sollen nachfolgend kurz charakterisiert werden. Anschließend wird kurz auf Meta-Suchmaschinen eingangen. Zu guter letzt werfen wir noch einen Blick darauf, welche Innovationen - zumindest nach aktuellem Stand - von den "Suchdiensten der Zukunft" zu erwarten sind. 2.1 Manuell betreute Suchdienste ("Web-Kataloge")Charakteristisch für manuell betreute Suchdienste (sogenannte "Web-Kataloge") ist, dass die Aufnahme neuer Seiten und deren Einordnung in die Datenbank von einer (menschlichen) Redaktion vorgenommen wird, die neu angemeldete WWW-Seiten besucht, anschließend nach bestimmten Kriterien klassifiziert und in eine thematisch orientierte Kategorie einordnet. Wie elaboriert das Kategorienraster und die Differenziertheit der vorgesehenen Themenbereiche ist, ist von Katalog zu Katalog und je nach dem Grundkonzept der jeweiligen Redaktion unterschiedlich. Das Beispiel in Abb. 2 zeigt die Einordnung der Website des "Hong Kong Institute of Marketing" im internationalen Katalog des Suchdienstes yahoo! und demonstriert zugleich die Effizienz von Web-Katalogen bei der gezielten Informationssuche: Da die Kategorisierung der verfügbaren WWW-Seiten sowohl thematisch als auch über mehrere Hierarchieebenen erfolgt, wird die Anzahl der Treffer, die ein Informationssuchender zusammengestellt bekommt, immer kompakter und überschaubarer, je weiter er seinen Interessenbereich durch Auswahl spezieller und speziellster Kategorien eingrenzt. Während im Beispiel die übergeordnete Kategorie "Business&Economy" insgesamt über eine halbe Million WWW-Seiten enthält, finden sich zwei Hierarchieebenen tiefer in der Kategorie "Institutes" nur noch überschaubare 24 Treffer für infrage kommende Angebote. 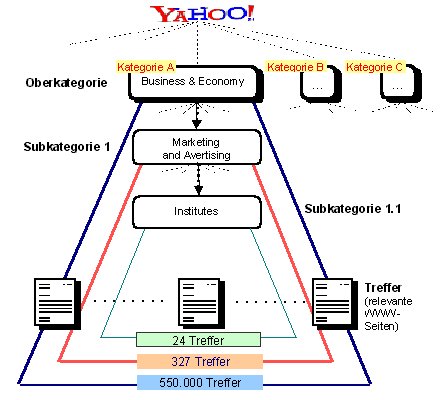 Abb. 2: Veranschaulichung zum Aufbau eines Suchkatalogs am Beispiel yahoo! (nach Beißwenger 2000, S. 158). Beispiele für Katalog-Suchdienste:  yahoo! web.de yahoo! web.de
Letztlich sind Web-Kataloge nichts anderes als umfangreiche Linklisten, die allerdings aufgrund ihrer thematischen und in den meisten Fällen auch hierarchischen Strukturierung eine hervorragende Möglichkeit darstellen, themenbezogen nach Online-Ressourcen zu recherchieren. Hinter dem relativ simplen Konzept steht eine menschliche Redaktion, die - ebenso wie der Anbieter einer Linkliste - neue Ressourcen überprüft, nach bestimmten Vorgaben thematisch klassifizert und dann unter einer oder mehreren Rubriken seines Katalogs als Linkangebot bereitstellt. Tatsächlich haben sich Web-Kataloge ursprünglich aus Linklisten entwickelt, deren Betreiber mit zunehmender Anzahl der gesammelten Links zu der Erkenntnis gelangten, dass eine übersichtliche Nutzung ihres Angebots nur dadurch weiterhin gewährleistet werden konnte, wenn man die Links thematisch und hierarchisch sortierte. Neben Webkatalogen mit allgemeiner Ausrichtung gibt es zu vielen Themen sogenannte "Spezialkataloge". Diese sammeln Ressourcen zu speziellen Themen und bieten diese - ebenfalls in rubrizierter Form - zum Weitersurfen an. Ein Beispiel für einen Spezialkatalog zum Thema Geschichte ist der Nachrichtendienst für Historiker. 2.2 (Volltext-)Suchmaschinen ("Crawler-Indizes")Als Suchmaschinen im engeren Sinne bezeichnet man nur solche Suchdienste, bei welchen die menschliche (subjektiv klassifizierende) Redaktion durch voll automatisierte Suchprogramme (so genannte "robots", "crawler" oder "Webspinnen") ersetzt ist, die unermüdlich das Netz nach neu hinzugekommenen Seiten durchforsten. Dass Programme natürlich letztlich keinen gleichwertigen Ersatz für eine menschliche Redaktion darstellen, liegt insofern auf der Hand, als ein Mensch bei der Beurteilung einer WWW-Seite (oder allgemein eines Textes) im Gegensatz zu einem Computerprogramm wesentlich kompetenter ist, deren zentrales Thema zu erfassen. Die Strategien, die Crawler-Programme verfolgen, um die Relevanz einer WWW-Seite für eine bestimmte Suchanfrage zu ermitteln, stützt sich auf Algorithmen, anhand derer Inhalt und Gegenstand einer WWW-Seite hinsichtlich der Frequenz bestimmter Schlüsselwörter zu rekonstruieren versucht werden. Letztlich jedoch indizieren die "Crawler" bei einer neu aufgefundenen Seite den kompletten Volltext, d.h. jedes im Text der Seite auftauchende Wort. Häufiger auftauchenden Wörtern wird dabei eine höhere Relevanz für den Inhalt der jeweiligen Seite beigemessen als nur einzeln auftauchenden Wörtern. Sucht man in einer Suchmaschine (wie beispielsweise Alta Vista) etwa nach dem Stichwort "Thomas Mann", so erhält man mehrere Tausend Treffer, von denen allerdings diejenigen als erste aufgeführt werden, denen das Programm auf der Grundlage seiner Berechnungen die größte Relevanz beimisst. Trotzdem sind die Suchergebnisse solcher Programme oftmals ebenso unbefriedigend wie umfangreich. So kann es bei einer Suchanfrage "Thomas Mann", die aus zwei suchrelevanten Ausdrücken (nämlich "Thomas" und "Mann") besteht, geschehen, dass man beispielsweise auch die Seite einer privaten Homepage als Treffer ausgegeben bekommt, auf welcher der Autor über einen Kinobesuch mit seinem Freund Thomas berichtet: "Mann, Thomas, sagte ich, lass uns doch mal wieder ins Kino gehn...". Die über eine Suchmaschine zutage geförderten Trefferlisten sind zwar oftmals wesentlich umfangreicher als die beim Nachschlagen in einem Web-Katalog erzielten, doch findet sich - eben aufgrund der maschinellen Ermittlung relevanter WWW-Dokumente zu einer Suchanfrage - unter den Ergebnissen oftmals so viel Irrelevantes, dass man spätestens nach Durchsicht des dreißigsten Treffers das ursprüngliche Rechercheansinnen enerviert aufgibt und sich mit dem (wenigen) begnügt, was man bereits gefunden hat. Überspitzt formuliert: »Oft gerät eine Suche zu einem Schlammbad an Irrelevanz. (Schimmeck 2001). Mittlerweile gibt es erfreuliche Bestrebungen, Suchmaschinen dahingehend zu optimieren, dass die Relevanz eines WWW-Dokuments für eine bestimmte Suchanfrage nicht mehr allein aufgrund von Algorithmen (z.B. hinsichtlich der Vorkommenshäufigkeit bestimmter Wörter) ermittelt wird, sondern auch noch unter Einbeziehung anderer Faktoren, die weitere Rückschlüsse darauf zulassen, wie bedeutsam die in einem Dokument angebotenen Informationen für die betreffende Suchanfrage sind. Ein rühmliches (und jedem Internet-Nutzer mit frustrierenden Rechercheerfahrungen wärmstens zu empfehlendes) Beispiel für diese "intelligentere" Generation von Suchmaschinen ist google: "Der Clou bei Google ist eine spezielle Software, die ihre Erfinder PageRank getauft haben. Sie saugt nicht nur einfach Daten von Hunderttausenden von Servern ab, sie untersucht auch das Beziehungsgeflecht im Web, stellt fest, welche Links wohin verweisen. Und die Anzahl der Querverweise auf eine bestimmte Seite entscheidet über deren Prominenz auf der Google-Ergebnisliste. Dabei spielt auch die Qualität der Seite eine Rolle, von der aus ein Link eingerichtet worden ist: So zählt etwa ein von einer seriösen Nachrichtenagentur ausgehender Hinweis mehr als der von einer privaten Homepage. Nähere Details zur Arbeitsweise von PageRank sind geheim - damit sie nicht kopiert werden kann." (Detailliertere Informationen zur Arbeitsweise von google finden sich in Schimmeck 2001). 2.3 Meta-Suchmaschinen und die unerträgliche Unmöglichkeit einer erschöpfenden Recherche im World Wide WebHin und wieder liest man (vor allem in der Eigenwerbung von Suchdiensten), erst durch diesen oder jenen Suchdienst würde das World Wide Web übersichtlich und als Ganzes recherchierbar. Um idealistischen Online-Rechercheuren an dieser Stelle (nicht jede, aber) eine gewisse Illusion zu nehmen: Kein Suchdienst "kennt" und "überblickt" das gesamte World Wide Web. Vielmehr deckt das Archiv eines Suchdienstes (selbst wenn es beständig erweitert wird) immer nur einen Bruchteil der tatsächlich im Netz verfügbaren Dokumente ab. Bei Web-Katalogen liegt dies darin begründet, dass jeder neu gefundene URL von einem menschlichen Bearbeiter geprüft werden muss; dies erfordert Zeit und Personalaufwand. Das Web aber wächst täglich exponentiell schneller, als den Mitgliedern der Belegschaften sämtlicher Katalog-Suchdienste zusammengenommen an Sichtungs- und Archivierungspotential zur Verfügung steht. Suchmaschinen dagegen arbeiten wesentlich schneller: Ein vollautomatisches Crawler-Programm kann die Indizierung und Archivierung einer neu gefundenen WWW-Seite binnen Sekunden leisten. Dennoch finden auch Suchmaschinen bei weitem nur einen Teil der tatsächlich im Web verfügbaren Dokumente. Dies liegt daran, dass Crawler-Programme bei ihrer Pirsch nach ihnen noch unbekannten und/oder neuen WWW-Dokumenten letztlich nach derselben Strategie vorgehen wie jeder "Online-Surfer" auch: Ausgehend von einer bereits bekannten WWW-Seite werden sämtliche der auf dieser Seite angebotenen Links verfolgt; findet sich dabei etwas Neues, so wird es indiziert und dem Archiv einverleibt. Je mehr Links auf ein WWW-Dokument verweisen, desto größer ist daher die Wahrscheinlichkeit, dass es (zumindest irgendwann) von den Crawlern einer Suchmaschine entdeckt wird. Dass offensichtlich aber auch die Suchmaschinen - trotz ihrer relativ schnellen Abarbeitung der Archivierungstätigkeit - bei weitem nicht das gesamte Web zu erfassen imstande sind, zeigt sich schon allein darin, dass man als Autor eines WWW-Dokuments bisweilen Wochen oder Monate warten muss, bis das eigene Dokument - selbst, wenn es vielfach "verlinkt" ist - tatsächlich über eine Suchmaschine recherchierbar ist. Überhaupt nicht oder nur mit geringer Wahrscheinlichkeit auffindbar sind für Suchmaschinen weiterhin solche WWW-Dokumente, auf deren URL von gar keinen oder nur wenigen anderen WWW-Dokumenten verwiesen wird. Aus diesem Grunde kamen vor einigen Jahren findige Programmierer auf die Idee, sogenannte "Meta-Suchmaschinen" (meta search engines) zu entwickeln. Das Prinzip der Meta-Suchmaschinen besteht darin, dass sie dem Online-Rechercheur den Aufwand abnehmen, nacheinander mehrere Suchdienste besuchen zu müssen, um letztlich eine zwar teilweise redundante, aber wenigstens ansatzweise befriedigende Liste an Suchergebnissen zu einer Suchanfrage zu erhalten. Eine Meta-Suchmaschinen bietet eine Benutzeroberfläche mit Suchmaske, in die eine Anfrage eingegeben werden kann, die dann gleichzeitig an mehrere andere Suchdienste (Kataloge wie Maschinen) gerichtet wird; die von den verschiedenen Suchdiensten an das Programm der Meta-Suchmaschine ausgegebenen Ergebnislisten werden anschließend zunächst miteinander verglichen und dann in einer neuen Liste an den Benutzer ausgegeben, in welcher Doppeltreffer eliminiert sind. Meta-Suchmaschinen sind zwar hinsichtlich der Qualität der von ihnen geliferten Ergebnisse abhängig von der Qualität derjenigen Suchdienste, die sie gesammelt absuchen, allerdings liefern sie in der Regel - eben durch die Parallel-Abfrage - deutlich umfangreichere Ergebnislisten als »normale« Suchdienste. Die Tatsache, dass Meta-Suchangebote im World Wide Web rege genutzt werden, bestätigt, dass Suchdienste (wie oben beschrieben) immer nur einen Bruchteil des Webs erfassen, was beim ernsthaften Recherchieren als unbefriedigend empfunden wird. Dies heißt aber nicht, dass eine Meta-Suchmaschine eine erschöpfende WWW-Recherche ermöglicht; vielmehr erfasst die von ihr ausgegebene Ergebnisliste zwar einen größeren Bruchteil der tatsächlich verfügbaren WWW-Ressourcen als "normale" Suchdienste - erschöpfend ist aber auch diese Ergebnisliste nicht. Das World Wide Web als Ganzes ist prinzipiell unüberschaubar. Die international bekannteste und älteste Meta-Suchmaschine ist der am Computer Science Department der University of Washington entwickelte Metacrawler. Eine weitere empfehlenswerte Meta-Suchmaschine ist MetaGer, beheimatet im Web-Angebot der Universität Hannover. 3. Das "Semantic Web" und die Suchdienste der ZukunftDas Problem der prinzipiellen Unüberschaubarkeit des World Wide Web zeigt sich beim Online-Recherchieren dahingehend, dass man sehr schnell bemerkt, dass verschiedene Suchdienste z.T. verschiedene Suchergebnisse liefern. Eine erschöpfende Recherche im dezentral organisierten Dokumentenbestand des World Wide Web ist unmöglich. Und selbst, wenn eine erschöpfende Recherche möglich wäre: Die Ergebnisliste wäre in den meisten Fällen ebenso unüberschaubar. Dies zeigt sich bereits, wenn man einer herkömmlichen Suchmaschine den Suchausdruck "Thomas Mann" aufgibt und eine Liste mit mehreren tausend Treffern erhält. Maximalziel einer erfolgreichen Online-Recherche sollte daher nicht sein, das komplette Web zu erfassen, sondern vielmehr, als Rechercheergebnis eine Trefferliste zu erhalten, die (a) überschaubar ist und (b) nur solche Treffer enthält, die für den eingegebenen Suchterm in hoher Weise relevant sind. Hierzu ist natürlich zum einen eine große Kapazität für die Auswertung und Archivierung von WWW-Dokumenten erforderlich, also am besten ein maschinelles Verfahren, da dieses - wie oben bereits beschrieben - wesentlich mehr Dokumente erfassen und abarbeiten kann als eine menschliche Redaktion. Der Nachteil einer maschinellen Erfassung und Auswertung von Dokumenten ist allerdings, dass diese weitaus weniger kompetent ist, das Thema einer Seite bzw. die Relevanz eines Dokuments für eine Suchanfrage zu ermitteln als ein menschlicher Redakteur. Beispielsweise ist es relativ unwahrscheinlich, dass ein WWW-Dokument, welches die Vorteile der Sonnenenergie beschreibt, zu einer Suchanfrage "Umweltschutz" als Ergebnis gelistet wird, wenn in ihm nicht mindestens einmal der Ausdruck "Umweltschutz" explizit enthalten ist. Herkömmliche Suchmaschinen versuchen, Thema und Gegenstand eines Dokuments anhand von Worthäufigkeiten u.dgl. zu ermitteln; semantische Zusammenhänge (z.B. dass Sonnenenergie eine Form der ökologischen Energiegewinnung darstellt und daher zum Bereich Umweltschutz gehört) können sie allerdings auf diese Weise nicht rekonstruieren. Semantische Zusammenhänge in einem Text zu erkennen, erfordert eine komplexe Kompetenz, in die ein differenziertes Sprach-, Welt- und Erfahrungswissen hineinspielen; über eine solche Kompetenz verfügt aber nur der Mensch. Daher gilt es, zu einer Optimierung von maschinell ermittelten Online-Recherchen den Menschen mit seiner semantischen Kompetenz miteinzubeziehen. Derjenige, der einen Text und damit bestimmte semantische Zusammenhänge stiftet, ist in der Regel der Autor bzw. der Produzent eines Dokuments. Gefragt ist nach neuen Standards für eine formale Modellierung von in Texten thematisierten Konzepten und Sachverhaltskomplexen für das World Wide Web, anhand welcher der Autor die Möglichkeit erhält, die von ihm angebotenen Inhalte nicht nur hinsichtlich ihrer Darstellung am Bildschirm, sondern auch in semantischer Hinsicht zu beschreiben, beispielsweise durch Beigabe von Meta-Daten, die die semantischen Zusammenhänge der mit bestimmten sprachlichen Ausdrücken assoziierten Begriffe explizieren. So könnte dem für die Anzeige am Bildschirm bestimmten Ausdruck "Sonnenergie" nicht nur die layoutorientierte Beschreibung "Fett, Times New Roman, Schriftgröße 14pt, zentriert" beigegeben werden, sondern darüber hinaus auch eine Beschreibung, die für das mit diesem Ausdruck Bezeichnete eine "ist-eine-Form-der"-Beziehung zum Begriff "ökologische Energiegewinnung" deklariert. "Ökologische Energiegewinnung" wiederum könnte als Teilbereich von "Umweltschutz" ausgewiesen werden (usw.). Semantische Beschreibungen dieser Art werden natürlich schnell recht komplex; daher bietet es sich an, diese nicht im Dokument selbst anzulegen, sondern in einem sogenannten "semantischen Netz", das den Teilen eines Dokuments oder einem thematisch zusammenhängenden Dokumentenverbund übergeordnet sein kann und die Einheiten dieses Verbunds als Objekte behandelt, deren Beziehungen untereinander als Ausprägungen semantischer Relationen beschrieben werden. Ein Ansatz für den Aufbau und die Beschreibung solcher "semantischer Netze" ist der Topic Map-Standard (ISO 13250:1999), mit dem sich sogenannte "Topics", die Konzepte und Relationen zwischen Konzepten repräsentieren können, dahingehend semantisch modellieren lassen, dass diese Modellierung anschließend für eine thematisch orientierte, wissensbasierte Navigation in Dokumenten und Dokumentenmengen genutzt werden kann. Eine exemplarische Veranschaulichung zu den Modellierungsprinzipien von Topic Maps findet sich in Abb. 3. Topic Maps oder vergleichbare Standards zur Modellierung von Meta-Daten (z.B. das Resource Description Framework, kurz RDF) könnten zum "GPS der globalen Bibliothek" werden und ganz neue, in erster Linie semantisch orientierte Generationen von Suchmaschinen ermöglichen, wenn sie vom W3C-Consortium und von den führenden Browserherstellern als neue, ergänzende Standards für die Dokumentenbeschreibung eingeführt bzw. unterstützt werden.  Abb. 3: Beispiel für eine Topic Map Abb. 3: Beispiel für eine Topic Map
Zum Weiterstöbern: Die kleine Suchfibel (Stefan Karzauninkat) XML Topic Maps (XTM) Resource Description Framework (RDF)Zum Weiterlesen: Tom Schimmeck: Wegweiser im World Wide Web. Die Herrscher der Portale. In: Geo Wissen 27. 2001, S. 130-137. Tom Schimmeck: Wegweiser im World Wide Web. Die Herrscher der Portale. In: Geo Wissen 27. 2001, S. 130-137.
|
 Zurück zum Seitenanfang Grundlagen I: Inhaltsübersicht Zurück zum Seitenanfang Grundlagen I: Inhaltsübersicht
|
| Urheberrechtlicher Hinweis |